Wie bewältigen gut die in meinem Beitrag über KI-Assistenten vorgestellten KI-Chatbots unterschiedliche Aufgaben? Um das herauszufinden, habe ich vier Tests durchgeführt. Jeder Test stellt andere Anforderungen an die Arbeitsleistung der jeweiligen KI. Diese Tests sind eine Ergänzung zu meinem Beitrag 10 KI-Assistenten unter der Lupe und sollen als Beispiele für mehr oder weniger „alltägliche“ Interaktionen mit KI-Assistenten privater Nutzer oder Freiberufler/innen dienen.
Lesezeit: ca. 25 Minuten
INHALT
- KI-Chatbots im Test
- Test 1 – Reiseplanung
- Test 2 – Textverarbeitung
- Test 3 – Kreativität
- Test 4 – Bildgenerierung
- Gesamtbewertung der Tests
- » KI-Chatbots Teil 2 – Rechtliche Aspekte, Zusammenfassung
KI-Chatbots im Test
Natürlich sind die Tests nicht repräsentativ und ich habe die Eignung der KI-Chatbots als Ersatz für Suchmaschinen nicht überprüft. Vorherige Tests haben jedoch ergeben, dass sie diesbezüglich eher zu Halluzinationen und falschen Informationen neigen, als bei den hier durchgeführten Test. Da ich mich bei KI-Chatbots, die ich eigentlich nicht nutze(n möchte), nicht registriert und kein Abonnement abgeschlossen habe, konnte ich leider Character AI, Claude AI und DeepSeek gar nicht testen.
Außerdem mussten die Prompts recht knapp gehalten werden, um zumindest die übrigen sieben kostenlos testen zu können und der KI genügend Tokens für die Antwort zu übrig zu lassen – siehe unter « Interaktionen, Tokens, Prompts. Analysen umfangreicher Dokumente oder die Bearbeitung größerer Projekte fielen somit ebenfalls weg. Die jeweiligen Original-Antworten kann du dir auf den Abbildungen (Screenshots: KI-Anbieter / eb) ansehen. In die Bewertung fließen sowohl testspezifische inhaltliche Aspekt, als auch Korrektheit und Aktualität sowie die Darstellung und die Dauer des Arbeitsvorgangs ein. Naturgemäß ist letztere bei sehr ausführlichen Antworten länger, was entsprechend zu berücksichtigen ist.
Test 1 – Reiseplanung
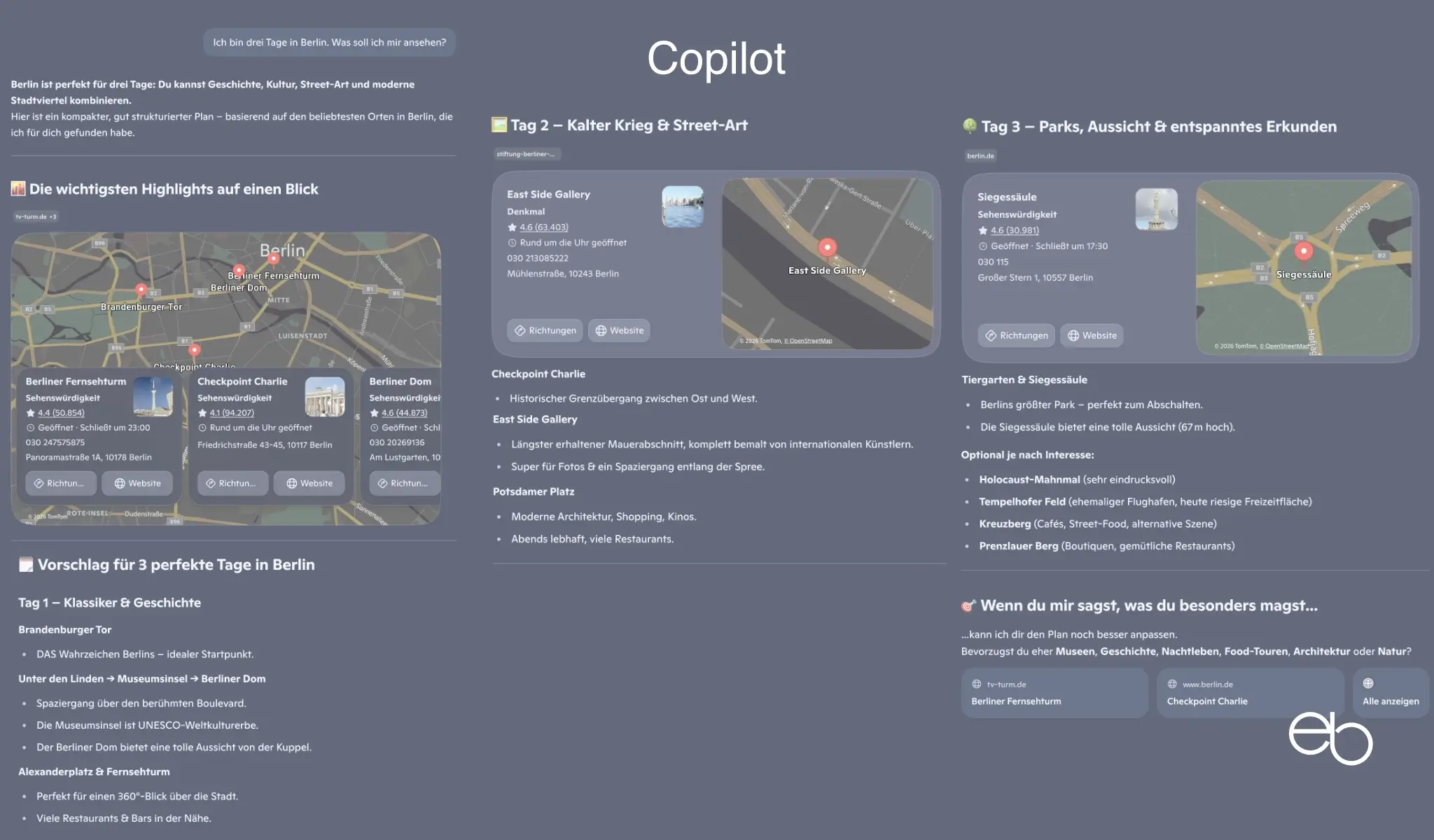
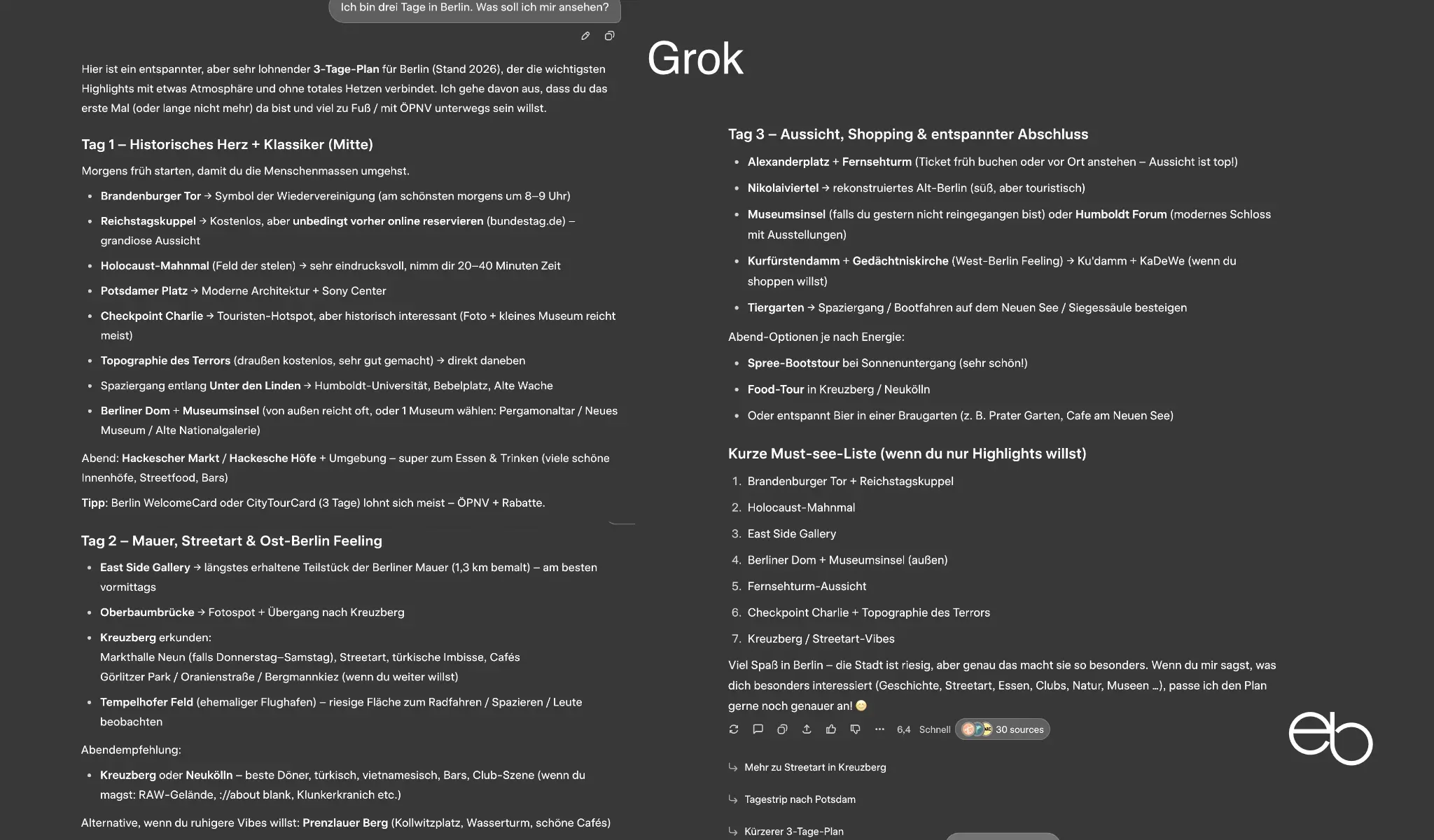
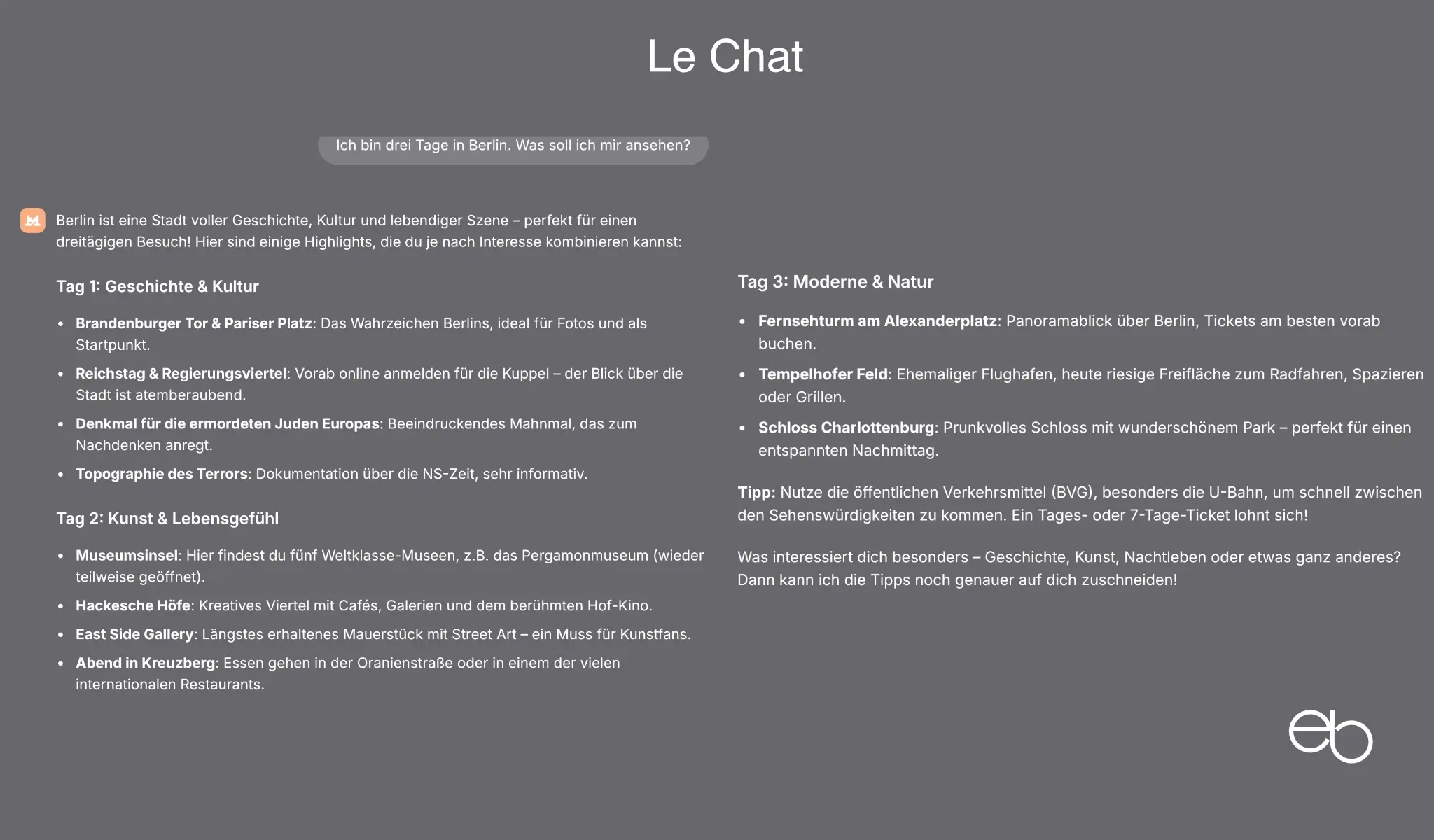
Die Aufgabenstellung für Test 1 lautete: „Ich bin drei Tage in Berlin. Was soll ich mir ansehen?“
Der Schwerpunkt der Bewertung liegt bei der Erwähnung der 13 Standardziele Brandenburger Tor, Reichstag, Museumsinsel, Berliner Dom, Holocaust-Mahnmal, East Side Gallery, Checkpoint Charlie, Alexanderplatz mit Fernsehturm, Potsdamer Platz, Hackesche Höfe, Kurfürstendamm, Unter den Linden und Tiergarten. Des weiteren sind die Anzahl der von der KI vorgeschlagenen, weniger populären Ziele, die Berücksichtigung von Geschichte, Kultur und Natur sowie die Erläuterungen zu den Zielen und Zusatzinformationen von Bedeutung.
Vorschläge der KI-Assistenten

- Standardziele: 11 , es fehlt der Potsdamer Platz, Kurfürstendamm
- Weniger populäre Ziele: 7
- Erläuterungen: Relativ kurz
- Zusatzinformationen: Essen, Nachtleben
- Fehler: Pergamonmuseum noch bis 2027 geschlossen
- Darstellung: Einfache übersichtliche Liste
- Dauer: ca. 28,2 Sekunden
- Standardziele: 10, es fehlen Reichstag, Hackesche Höfe, Kurfürstendamm
- Weniger populäre Ziele: 3
- Erläuterungen: Angemessen
- Zusatzinformationen: Essen, Shopping, Nachtleben
- Fehler: Keine offensichtlichen
- Darstellung: Übersichtliche Liste mit Standortverweisen für einige Ziele
- Dauer: ca. 28,5 Sekunden
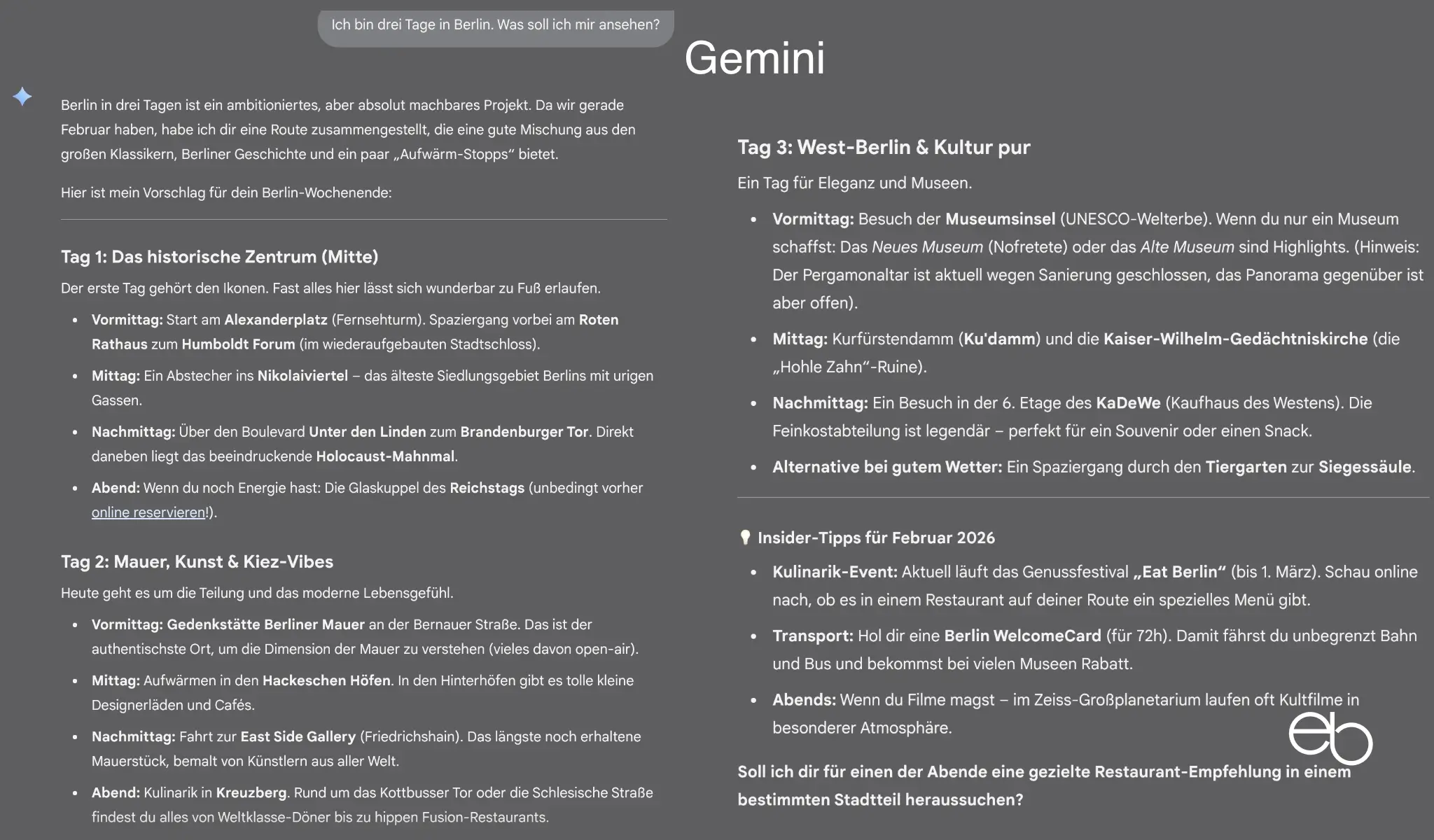
- Standardziele: 10, es fehlen Berliner Dom, Checkpoint Charlie, Potsdamer Platz
- Weniger populäre Ziele: 3
- Erläuterungen: Recht ausführlich
- Zusatzinformationen: Essen, Shopping, Nachtleben, Insider-Tipps
- Fehler: Keine offensichtlichen
- Darstellung: Übersichtliche Liste
- Dauer: ca. 11,6 Sekunden
- Standardziele: 12, es fehlt Potsdamer Platz
- Weniger populäre Ziele: 6
- Erläuterungen: Recht ausführlich
- Zusatzinformationen: Essen, Shopping, Nachtleben, Tipps
- Fehler: Keine offensichtlichen
- Darstellung: Übersichtliche Liste, kurze Must-see-Liste, Quellenverweise
- Dauer: ca. 20 Sekunden
- Standardziele: 7, es fehlen Berliner Dom, Checkpoint Charlie, Potsdamer Platz, Kurfürstendamm, Unter den Linden und Tiergarten
- Weniger populäre Ziele: 4
- Erläuterungen: Ausreichend
- Zusatzinformationen: Essen, Nachtleben, Tipp
- Fehler: Pergamonmuseum noch bis 2027geschlossen
- Darstellung: Kurze, aber übersichtliche Liste
- Dauer: ca. 12,3 Sekunden

- Standardziele: 8, es fehlen Berliner Dom, Holocaust-Mahnmal, Alexanderplatz mit Fernsehturm, Hackesche Höfe, Kurfürstendamm
- Weniger populäre Ziele: 3
- Erläuterungen: Angemessen
- Zusatzinformationen: Essen, Nachtleben, Tipps
- Fehler: Pergamonmuseum noch bis 2027 geschlossen
- Darstellung: Übersichtliche Liste
- Dauer: ca. 12 Sekunden

- Standardziele: 10, es fehlen Potsdamer Platz, Kurfürstendamm, Unter den Linden
- Weniger populäre Ziele: 4
- Erläuterungen: Angemessen
- Zusatzinformationen: Essen, Nachtleben, Tipps
- Fehler: Pergamonmuseum noch bis 2027 geschlossen, Deutschlandticket kostet 63,00 Euro.
- Darstellung: Übersichtliche Liste
- Dauer: ca. 14,3 Sekunden
Auswertung von Test 1
Wirklich mangelhaft ist keines der Ergebnisse ausgefallen. Alle KI-Chatbots zeigen ihre Vorschläge in Listenform, berücksichtigen die unterschiedlichen Interessengebiete und machen Angaben zum Essen gehen und zur Abendgestaltung. Die größte Auswahl an Zielen findest du bei ChatGPT und Grok, gefolgt von Perplexity. Am wenigsten Vorschläge liefern Lumo und Le Chat. Bei den Erläuterungen und Zusatzinformationen liegen Gemini und Grok vorne. Grok punktet zusätzlich mit Quellenverweisen und Copilot mit der Einbindung von Standortkarten.
Ein Mangel an Aktualität zeigt sich bei ChatGPT, Le Chat, Lumo und Perplexity. Es gibt keinen Hinweis, dass das Pergamonmuseum aktuell noch renoviert wird und bei Perplexity ist zusätzlich die Preisangabe für das Deutschlandticket falsch. Hinsichtlich der Dauer bis zur Fertigstellung der Antwort und unter Berücksichtigung des generierten Informationsumfangs ist Gemini der klare Sieger, ChatGPT brauchte mehr als doppelt so lange und Grok hat am längsten nachgedacht, bevor die Antwort erschien. Zusammengefasst wäre bei diesem Test die Reihenfolge:
Grok und Gemini – Copilot und Perplexity – ChatGPT – Lumo und Le Chat
Test 2 – Textverarbeitung
Die Aufgabenstellung für Test 2 lautete: „Fasse diesen Text zusammen.“
Text-Vorgabe
Verbrauch von Ressourcen
Zum einen steigt der Bedarf an Rohstoffen wie beispielsweise Kobalt und Lithium für die Chips. Daraus resultieren in den jeweiligen Abbaugebieten nicht nur Umweltschäden, sondern auch soziale Probleme.
Zum anderen geht der Betrieb dieser Rechenzentren mit einem hohen Strom- und Wasserbraucheinher. Um die großen Strommengen zu erzeugen, wird wieder vermehrt auf fossile Energien zurückgegriffen, was einen erhöhten Ausstoß von klimaschädlichem CO2 zur Folge hat. Auch gibt es bereits Überlegungen, stillgelegte Kernkraftwerke wieder in Betrieb zu nehmen.
Um eine Vorstellung von den Dimensionen des Stromverbrauchs zu bekommen, seien hier einige Beispiele genannt: Ein Trainingslauf des Modells GPT-3 mit 175 Milliarden Parametern verbraucht ca. 1.287 Megawattstunden Strom, was rund 502 Tonnen CO2 oder einem jährlichen CO2-Ausstoß von 112 PKW entspricht. Einerseits zeigt Mistral, dass es auch stromsparender geht. Eine 400-Token-Antwort eines KI-Assistenten erzeugt nur 1,14 g CO2. Allerdings summiert sich auch dies bei mehreren Millionen Abfragen schnell auf einige Tonnen. Andererseits dürften neuere und noch leistungsstärkere Modelle beim Stromverbrauch noch höher liegen. So gehen Studien davon aus, dass der Stromverbrauch von Rechenzentren für KI und Digitalisierung in Europa bis 2030 auf über 150 Terawattstunden steigen wird.
Der dritte Punkt ist der immense Wasserbedarf, der zur Kühlung der Server notwendig ist. Techzeitgeist gibt für 2025 in einem Beitrag einen Wasserbedarf für den Betrieb der KI-Rechenzentren und die Stromerzeugung von 312 bis 765 Milliarden Liter an. Bei einem Chat mit einem KI-Assistenten mit 10 bis 50 Fragen wird ca. ein halber Liter Wasser verbraucht (Quelle: Change Magazin).
Wirklich belastbare Werte sind sowohl für den Strom- als auch für den Wasserverbrauch nur schwer zu finden, da sich die Betreiber der KI-Assistenten sehr bedeckt halten. Zwar haben OpenAI, Microsoft, Google und Mistral eine Umweltstrategie, aber eine Ökobilanz ist nur bei den letzten drei verfügbar, bei OpenAI nur teilweise. Eine transparente Metrik liefert nur Mistral, Google teilweise und Microsoft sowie OpenAI gar nicht.
Auswirkungen auf die Arbeitswelt
Wie bei vielen Neuerungen in den vergangenen Jahrzehnten und Jahrhunderten neigen Menschen dazu, zunächst in Panik zu verfallen. Auch hinsichtlich des Einsatzes von KI, Chatbots und KI-Assistenten war die erste Reaktion, dass KI die Arbeit von Menschen ersetzt und somit viele arbeitslos würden. Das hat sich bisher so nicht bestätigt. Auch in Zukunft wird es viele Berufe, wie zum Beispiel im sozialen oder Pflegebereich, geben, in denen Maschinen und nichts anderes ist KI, keine Menschen vollständig ersetzen kann.
Darüber hinaus kommt auch die KI nicht ohne Menschen aus. Irgendjemand muss für die notwendige Infrastruktur sorgen, sie betreuen sowie KI-Assistenten und Chatbots programmieren und kontrollieren. Insbesondere KI-Assistenten können nur arbeiten, wenn Menschen mit ihnen interagieren, ihre Ergebnisse überprüfen und weiter verarbeiten. Eine Studie des Instituts für Arbeitsmarkt- und Berufsforschung spricht deshalb auch von einer Verschiebung von 1,6 Millionen Jobs. Das bedeutet, dass zwar einige Jobs wegfallen, andere aber auch neu entstehen oder wichtiger werden.
Herbert Weber vom IAB sagt dazu: KI wird am Arbeitsmarkt nicht zu einem Einbruch führen, sondern zu einem Umbruch. … Was KI in fünf Jahren können wird, das wissen wir jetzt noch nicht. Aber wie wir uns selber weiterentwickeln können mit unseren Kompetenzen, das haben wir in der Hand.
Bei dem Text handelt es sich um einen von mir selbst verfassten Entwurf für einen anderen Beitrag, der noch nicht veröffentlich ist. Im Original enthaltene Quellenangaben zu einzelnen Aussagen habe ich für diesen Test zuvor entfernt.
Bewertet wird, ob alle wichtigen Aussagen des Originals enthalten sowie korrekt und verständlich wiedergegeben sind. Gibt es sprachliche Fehler und wie ist der Schreibstil / könnte die Zusammenfassung eins-zu-eins übernommen werden? Unter Sonstiges ist außerdem angegeben, ob freie Interpretationen oder Halluzinationen ausgegeben wurden und ob das eigene Produkt hervorgehoben wird oder Mitbewerber (OpenAI, Google, Microsoft, Mistral) unerwähnt bleiben.
Vorschläge der KI-Assistenten
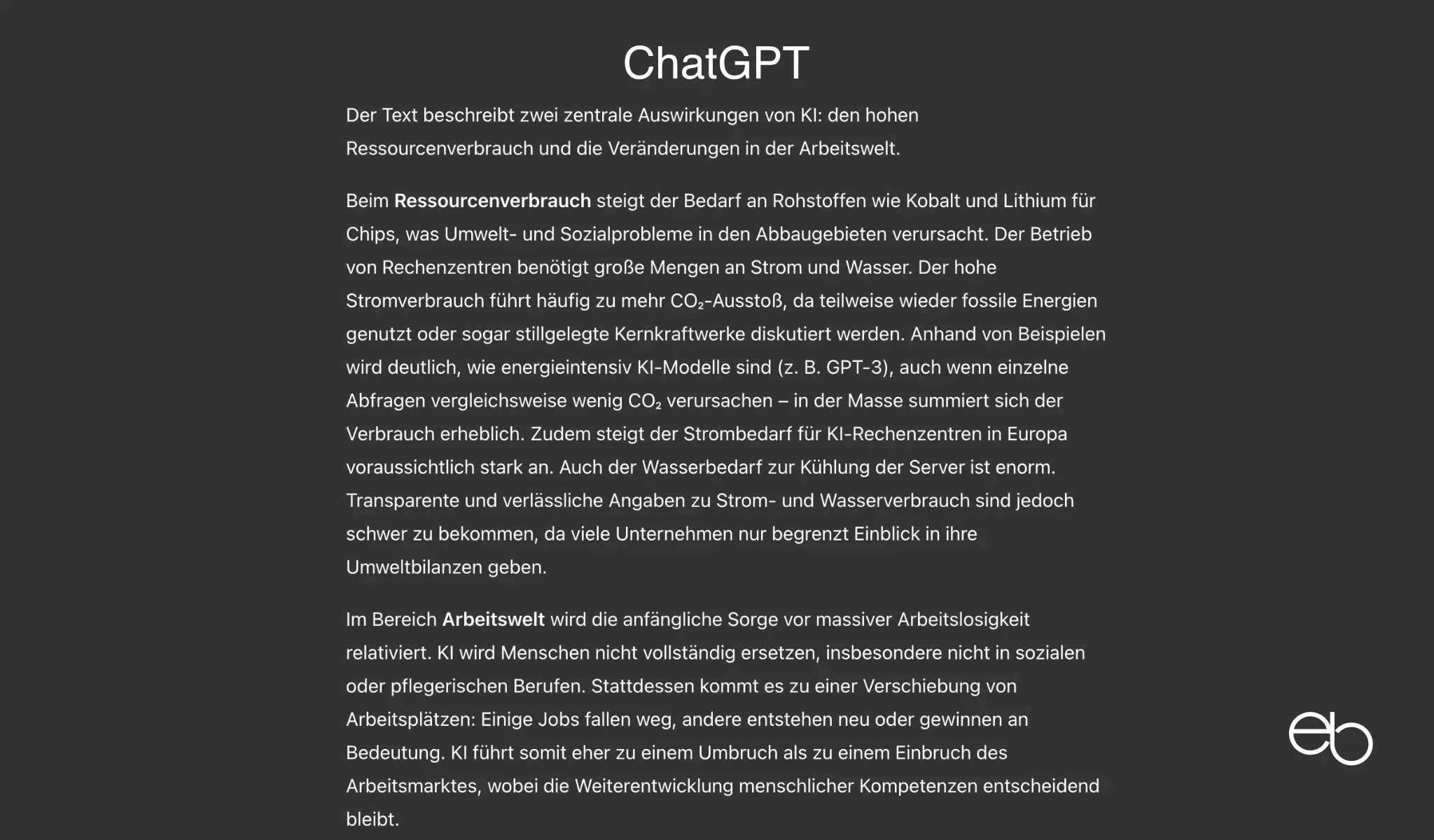
- Vollständigkeit: Zahlenangaben und neue Arbeitsfelder fehlen
- Korrekte Wiedergabe: Der Sinn des letzten Satzes wurde nicht richtig erfasst.
- Verständlichkeit: Gut
- Schreibstil / übernehmen: Kurze Sätze, zu wenig gegliedert / eher nein
- Sonstiges: Sehr frei formuliert, teilweise interpretiert; kein Unternehmen wird erwähnt
- Dauer: ca. 10 Sekunden

- Vollständigkeit: Ja, mit Einschränkung
- Korrekte Wiedergabe: Ja
- Verständlichkeit: Gut
- Schreibstil / übernehmen: Listenform / eher ja
- Sonstiges: Kein Unternehmen wird erwähnt
- Dauer: ca. 11 Sekunden

- Vollständigkeit: Wasserverbrauch 2025 fehlt
- Korrekte Wiedergabe: Ja
- Verständlichkeit: Sehr gut, gute Gliederung
- Schreibstil / übernehmen: Listenform / ja
- Sonstiges: Nur OpenAI wird (negativ) erwähnt
- Dauer: ca. 8,5 Sekunden

- Vollständigkeit: Ja
- Korrekte Wiedergabe: Ja
- Verständlichkeit: Gut, gute Gliederung
- Schreibstil / übernehmen: Listenform, stichwortartig / eher nein
- Sonstiges: Teilweise interpretiert; OpenAI, Google und Mistral werden erwähnt; zusätzliche Kurzfassung und Quellenangaben
- Dauer: ca. 9,5 Sekunden

- Vollständigkeit: Angaben zur Energiegewinnung fehlen
- Korrekte Wiedergabe: Ja
- Verständlichkeit: Gut, gute Gliederung
- Schreibstil / übernehmen: Listenform, sehr kurz / eher nein
- Sonstiges: Sehr frei formuliert; OpenAI, Google und Microsoft werden erwähnt, Mistral hervorgehoben
- Dauer: ca. 9,9 Sekunden

- Vollständigkeit: Verweis auf Atomkraftwerke fehlt
- Korrekte Wiedergabe: Ja
- Verständlichkeit: Gut, gute Gliederung
- Schreibstil / übernehmen: Listenform / eher ja
- Sonstiges: OpenAI, Google, Microsoft und Mistral werden erwähnt
- Dauer: ca. 9,3 Sekunden

- Vollständigkeit: Verweis auf Atomkraftwerke fehlt
- Korrekte Wiedergabe: Wasserverbrauch 2025 soll
- Verständlichkeit: Gut, gute Gliederung
- Schreibstil / übernehmen: Relativ frei, Listenform / eher ja
- Sonstiges: OpenAI und Microsoft werden erwähnt
- Dauer: ca. 7 Sekunden
Auswertung von Test 2
Auch bei Test 2 hat keiner der KI-Assistenten vollkommen versagt. Dennoch gibt es deutliche Unterschiede. Nur Grok hat alle wichtigen Aspekte wiedergegeben, bei den anderen fehlen Zahlenangaben und Arbeitsfelder (ChatGPT), vollständige Angaben zur Energiegewinnung (Le Chat, Lumo, Perplexity) und bei Gemini Zahlen zum Wasserverbrauch. ChatGPT hat den Sinn und Perplexity den Inhalt je eines Satzes nicht ganz korrekt wiedergegeben. Verweise auf Mitbewerber fehlen bei ChatGPT und Copilot ganz, andere haben nur einzelne und nur Le Chat und Lumo haben alle erwähnt.
Bis auf ChatGPT haben alle die Zusammenfassung in Listenform erstellt, was sehr übersichtlich und gut lesbar ist. Hinsichtlich des Schreibstils reicht die Palette von sehr nah am Original bis zu sehr frei formulierten und zum Teil interpretierten Aussagen wie bei ChatGPT. Sprachliche Fehler gab es nicht. Dennoch müssten, je nach Modell und anschließendem Verwendungszweck, die Ergebnisse mehr oder weniger an den eigenen Stil angepasst werden. In Relation zum Arbeitsaufwand antworteten Gemini und Perplexity am schnellsten und ChatGPT sowie Le Chat am langsamsten. Zusammengefasst wäre bei diesen Test die Reihenfolge:
Lumo und Grok – Gemini, Copilot und Perplexity – Le Chat – ChatGPT
Test 3 – Kreativität
Die Aufgabenstellung für Test 3 lautete: „Erstelle ein Farbkonzept für eine Website. Hauptfarbe: Ruby Red a50021 plus eine Sekundärfarbe, eine Kontrastfarbe und eine hellere Farbe für den Hintergrund.“
Bezüglich der Kreativität sollten mindestens drei zusätzliche Farben vorgeschlagen werden. Außerdem wird bewertet, ob es Erläuterungen zu den einzelnen Farben / zu deren Einsatz / zum Gesamtkonzept gibt, ob die Farbbezeichnungen angegeben sind und ein kopierbarer CSS-Code zur Verfügung gestellt wird. Um das Farbkonzept besser beurteilen zu können, habe ich nachträglich auf den Abbildungen jeweils das kreierte Farbschema in der von mir vorgegebenen Reihenfolge hinzugefügt.
Vorschläge der KI-Assistenten
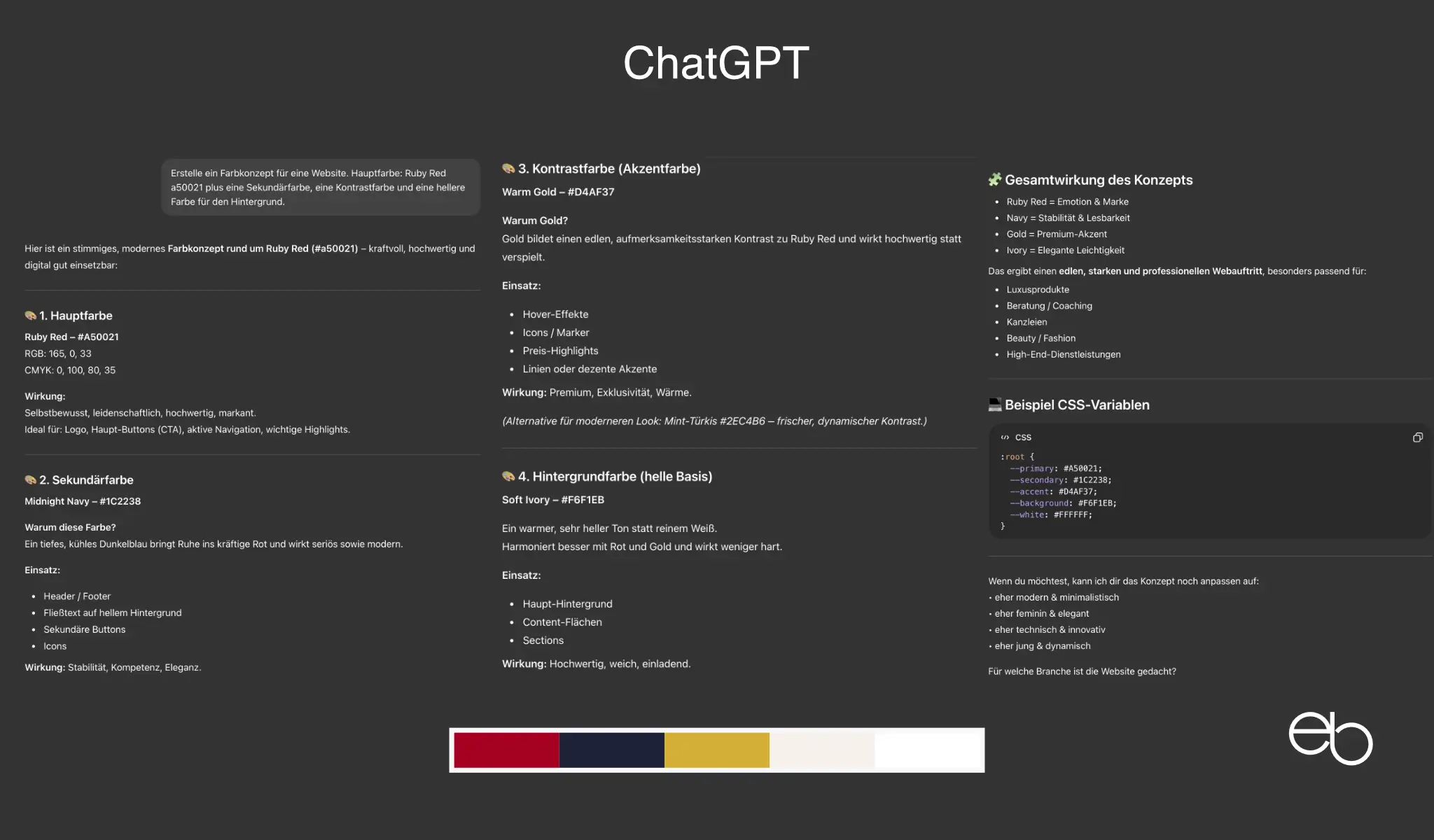
- Kreativität: 3 plus weiß plus 1 Alternative, stimmig, deutliche Kontraste
- Erläuterungen: Wirkung / Ja / Ja
- Farbbezeichnungen: Name und Hex-Code
- CSS-Code: Ja
- Dauer: ca. 18 Sekunden
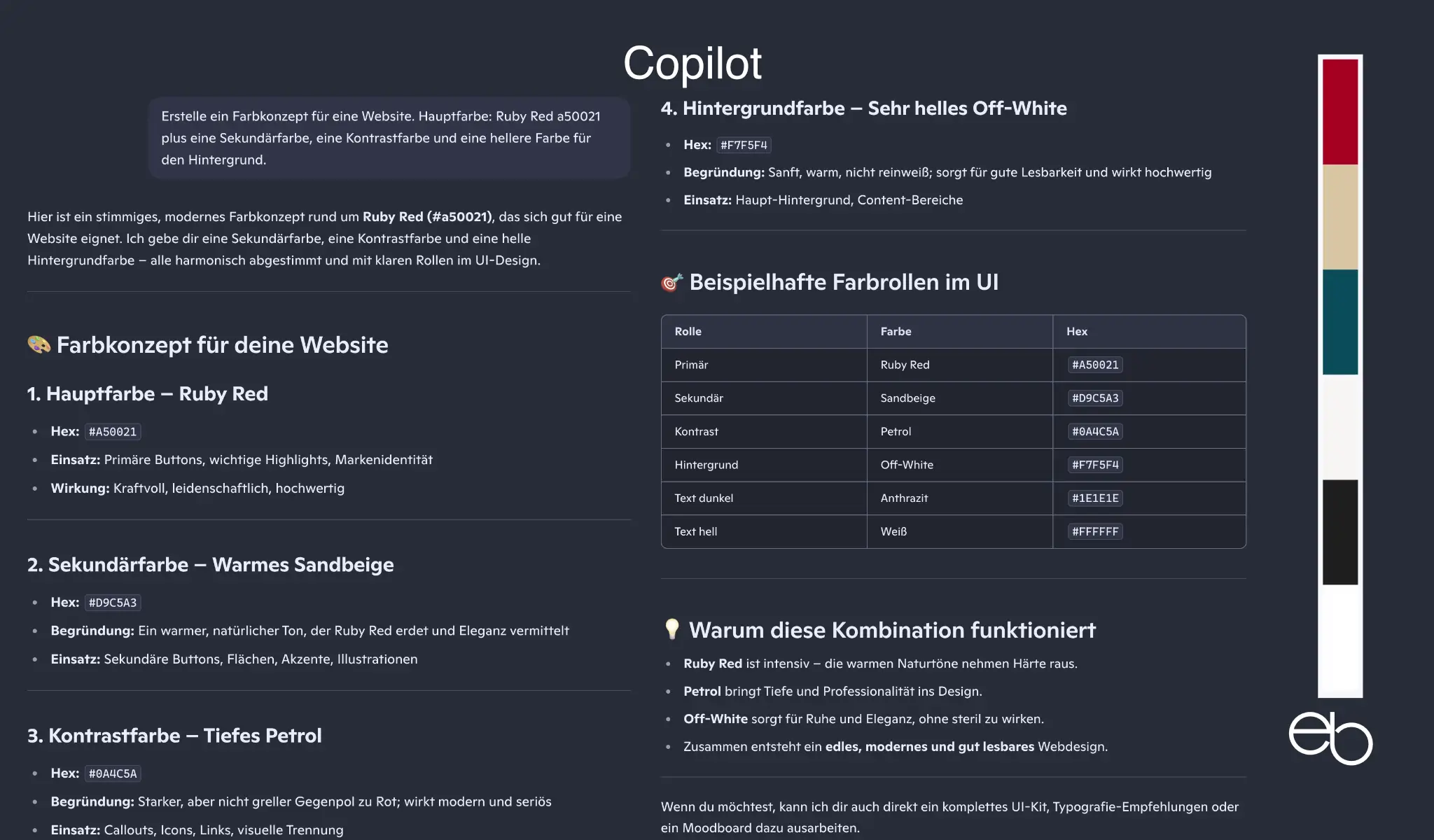
- Kreativität: 3 plus Anthrazit und weiß, stimmig, deutliche Kontraste
- Erläuterungen: Begründung / Ja / Ja
- Farbbezeichnungen: Name und Hex-Code
- CSS-Code: Nein
- Dauer: ca. 13,5 Sekunden
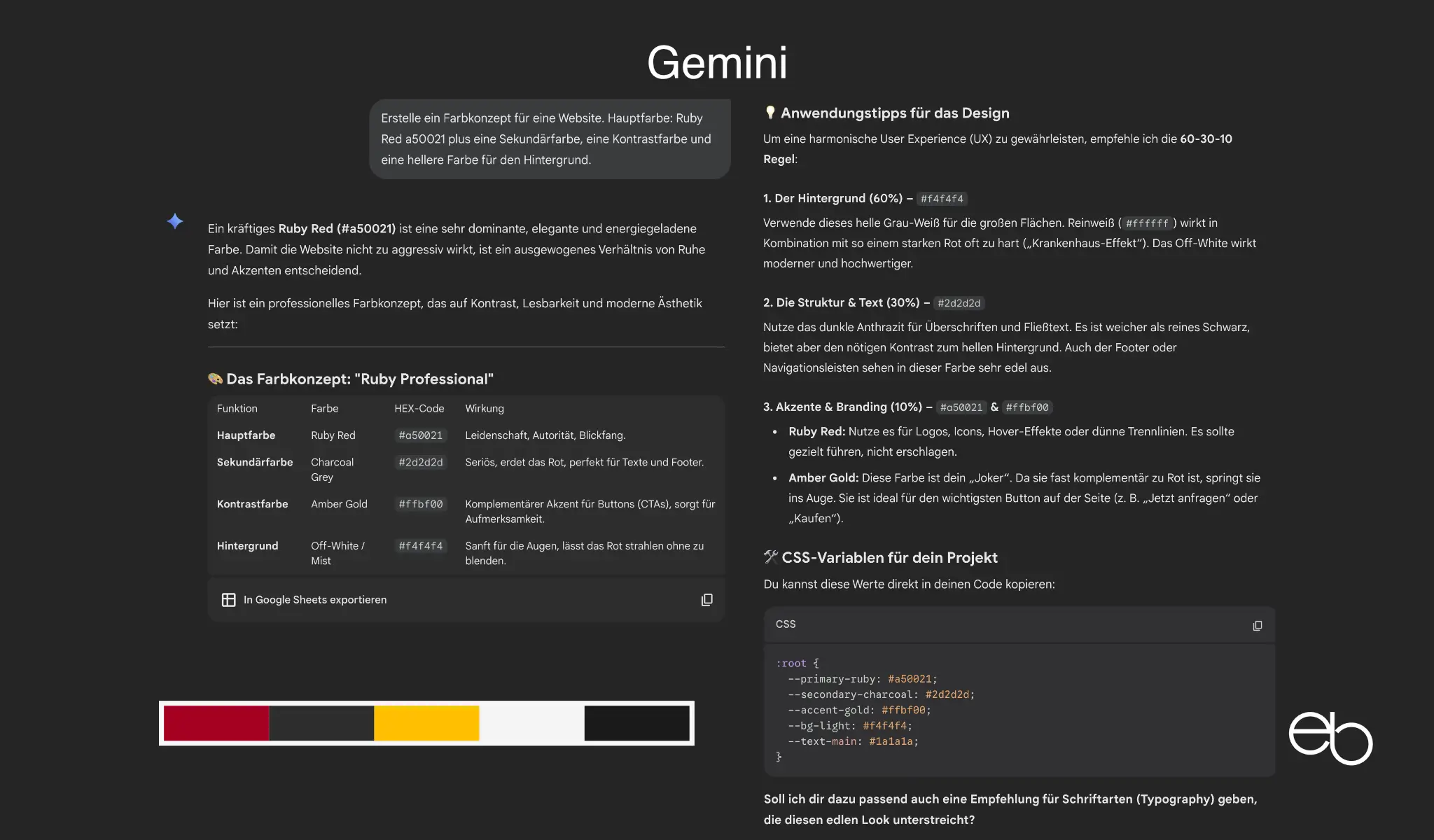
- Kreativität: 3 plus Schwarz, stimmig, deutlicher Kontrast
- Erläuterungen: Wirkung / Ja / (Ja)
- Farbbezeichnungen: Name und Hex-Code
- CSS-Code: Ja
- Dauer: ca. 10 Sekunden
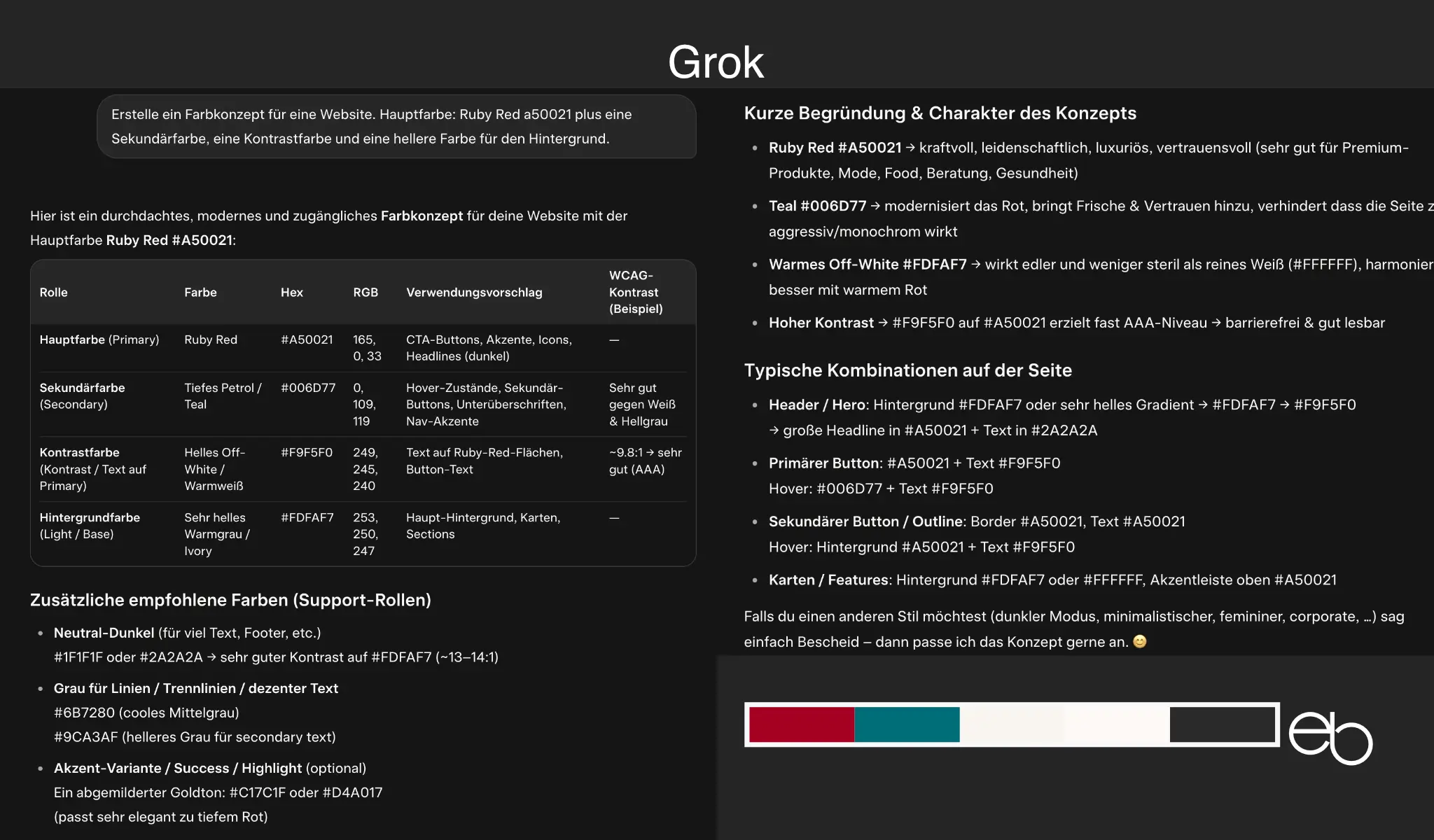
- Kreativität: 3 plus Schwarz plus 2 Alternativen, wenig kreativ, zu helle Kontrastfarbe
- Erläuterungen: Wirkung / Ja / Nein
- Farbbezeichnungen: Name und Hex-Code
- CSS-Code: Nein
- Dauer: ca. 11,9 Sekunden
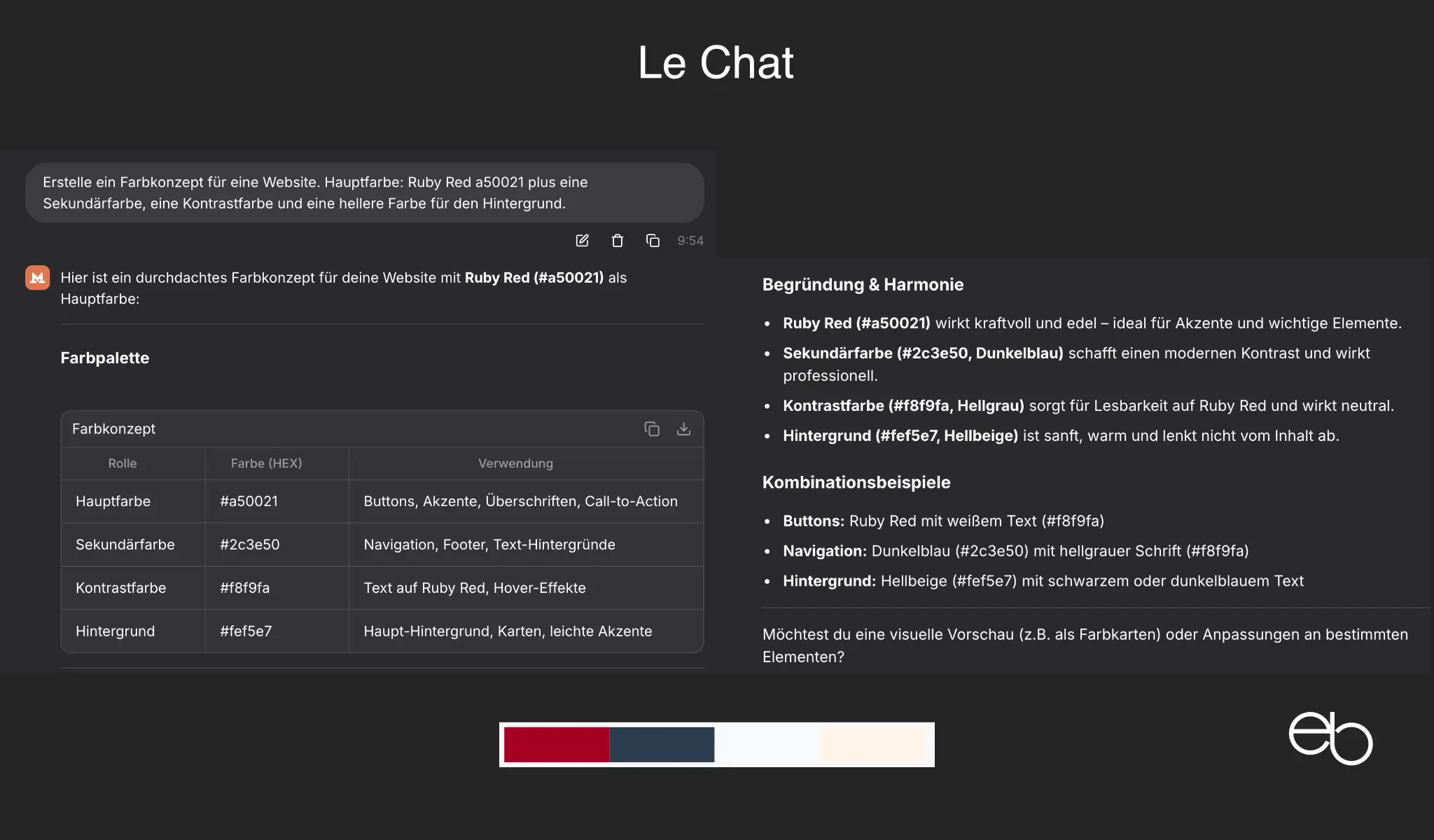
- Kreativität: 3, wenig kreativ, zu helle Kontrastfarbe
- Erläuterungen: Wirkung / Ja / Nein
- Farbbezeichnungen: Name und Hex-Code
- CSS-Code: Nein
- Dauer: ca. 11 Sekunden
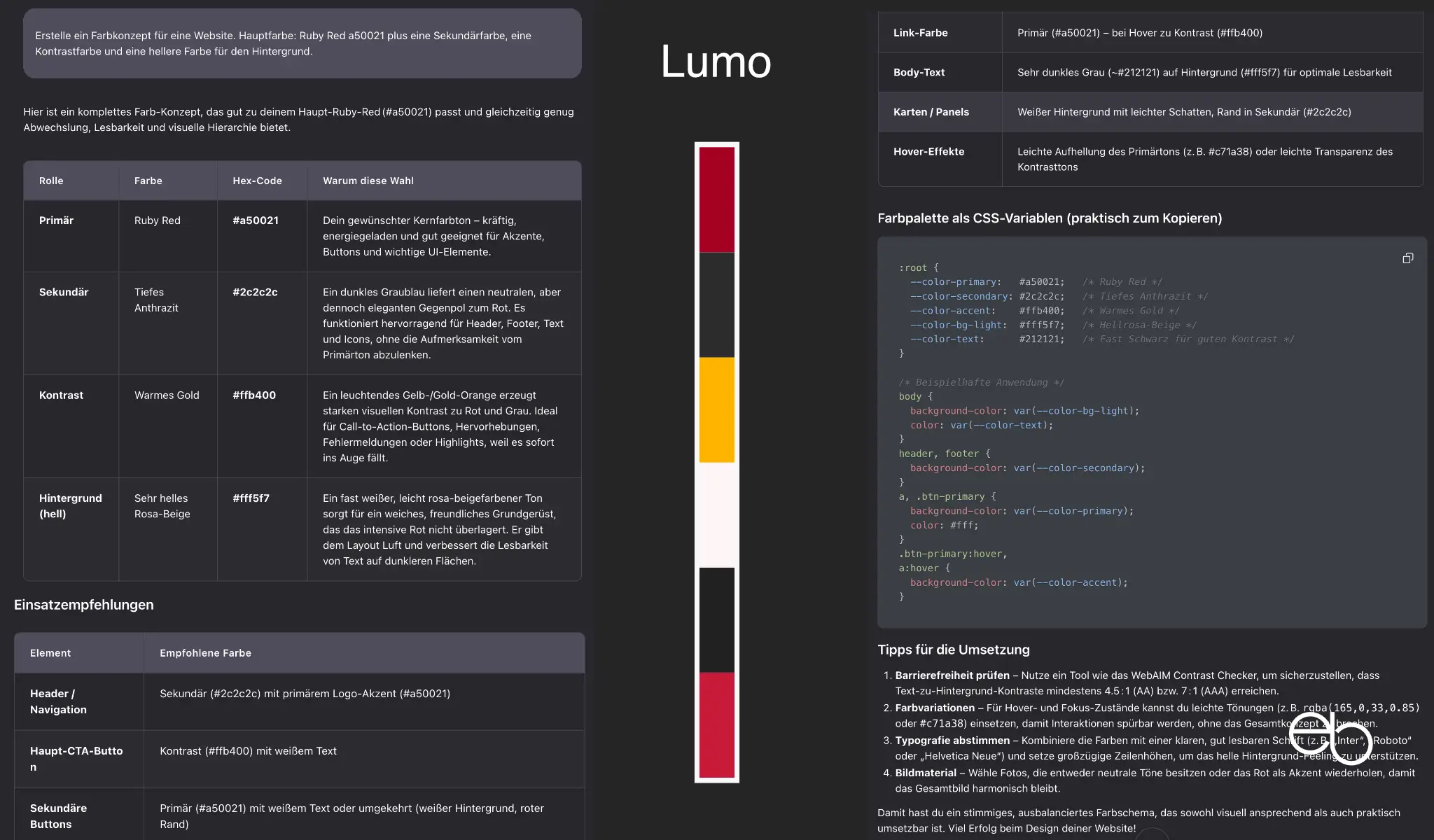
- Kreativität: 3 plus 2, sehr stimmig, deutlicher Kontrast
- Erläuterungen: Wirkung / Ja / Nein, aber zusätzliche Tipps
- Farbbezeichnungen: Name und Hex-Code
- CSS-Code: Ja
- Dauer: ca. 15 Sekunden

- Kreativität: 3 + weiß, stimmig, ausreichender Kontrast
- Erläuterungen: Wirkung / Ja / Ja
- Farbbezeichnungen: Name und Hex-Code
- CSS-Code: Nein
- Dauer: ca. 7,5 Sekunden
Auswertung von Test 3
Jeder der KI-Assistenten hat die Aufgabe erfüllt, wenn auch die Ergebnisse ähnlich deutlich voneinander abweichen wie bei den vorangegangenen Tests. Zwar war Perplexity am schnellsten, lieferte aber auch die wenigsten Informationen. Zur seiner Ehrenrettung muss jedoch gesagt werden, dass bei diesem KI-Assistenten der Schwerpunkt auf Texten liegt. Trotzdem hat er die Antwort nicht verweigert – siehe » Test 4 – Bildgenerierung. Für die Wahl des individuell passenden Farbkonzepts, spielen am Ende natürlich auch der persönliche Geschmack und die Art der Website, auf der es angewendet werden soll, eine gewisse Rolle.
Bei der Kreativität liegen aus Webdesigner-Sicht ChatGPT, Copilot, Gemini und Lumo vorne und Perplexity und Grok im Mittelfeld. Le Chat bildet das Schlusslicht. Bezüglich der anderen Kriterien liefern ChatGPT und Lumo die meisten Informationen. Einen CSS-Code bieten nur ChatGPT, Gemini und Lumo an. Abgesehen von Perplexity hat Gemini die Aufgabe am schnellsten erledigt, Le Chat und Grok folgen knapp dahinter und ChatGPT benötigte die längste Zeit. Unter Berücksichtigung des Informationsumfangs und der Darstellungsweise ist ChatGPT jedoch vor Le Chat und Perplexity einzuordnen. Insgesamt gesehen sieht die Bewertung wie folgt aus:
Lumo und Gemini – ChatGPT und Copilot – Perplexity – Grok – Le Chat
Test 4 – Bildgenerierung
Die Aufgabenstellung für Test 4 lautete: „Erstelle ein Header-Bild für die Webdesigner-Website „PrimaWebdesign“. Nutze auch die Farben Ruby Red und Teal. Stil: Flat-Design, Grafisch, PC-Motiv.“
Die genannte Website existiert nicht und ich habe absichtlich nur wenige Vorgaben gemacht, um zu sehen, wie „einfallsreich“ die KI-Assistenten von sich aus sind. Die Farbvorgabe ist an das in Test 3 am häufigsten vorgeschlagene Konzept angelehnt. Da sich alle weitgehend an das Grundkonzept hielten, fließen in die Bewertung nur die Individualität des Bildes, dessen Komplexität sowie eventuell vorhandene, zusätzliche Anmerkungen und die Generierungsdauer ein.
Vorschläge der KI-Assistenten

Diese Aufgabe konnten drei der zuvor mitgetesteten KI-Assistenten nicht ausführen. Das Modell von Perplexity ist nur auf den Umgang mit Texten spezialisiert, in Lumo ist (noch) keine Bildgenerierung integriert. Bei ChatGPT war eine Registrierung notwendig, der Chatbot fragte jedoch nach dem Stilwunsch. Auch bei Gemini und Le Chat war eine Anmeldung notwendig, jedoch besitze ich bei beiden ein Konto und konnte den Test somit durchführen. Nur Copilot und Grok antworteten auch ohne Registrierung.

- Individualität: Gering, überladen
- Komplexität: Hoch, viele kleine Details plus Website-Name
- Anmerkungen: Fragen nach Details, Anpassungs-Ideen
- Dauer: ca. 1 Minute 14 Sekunden
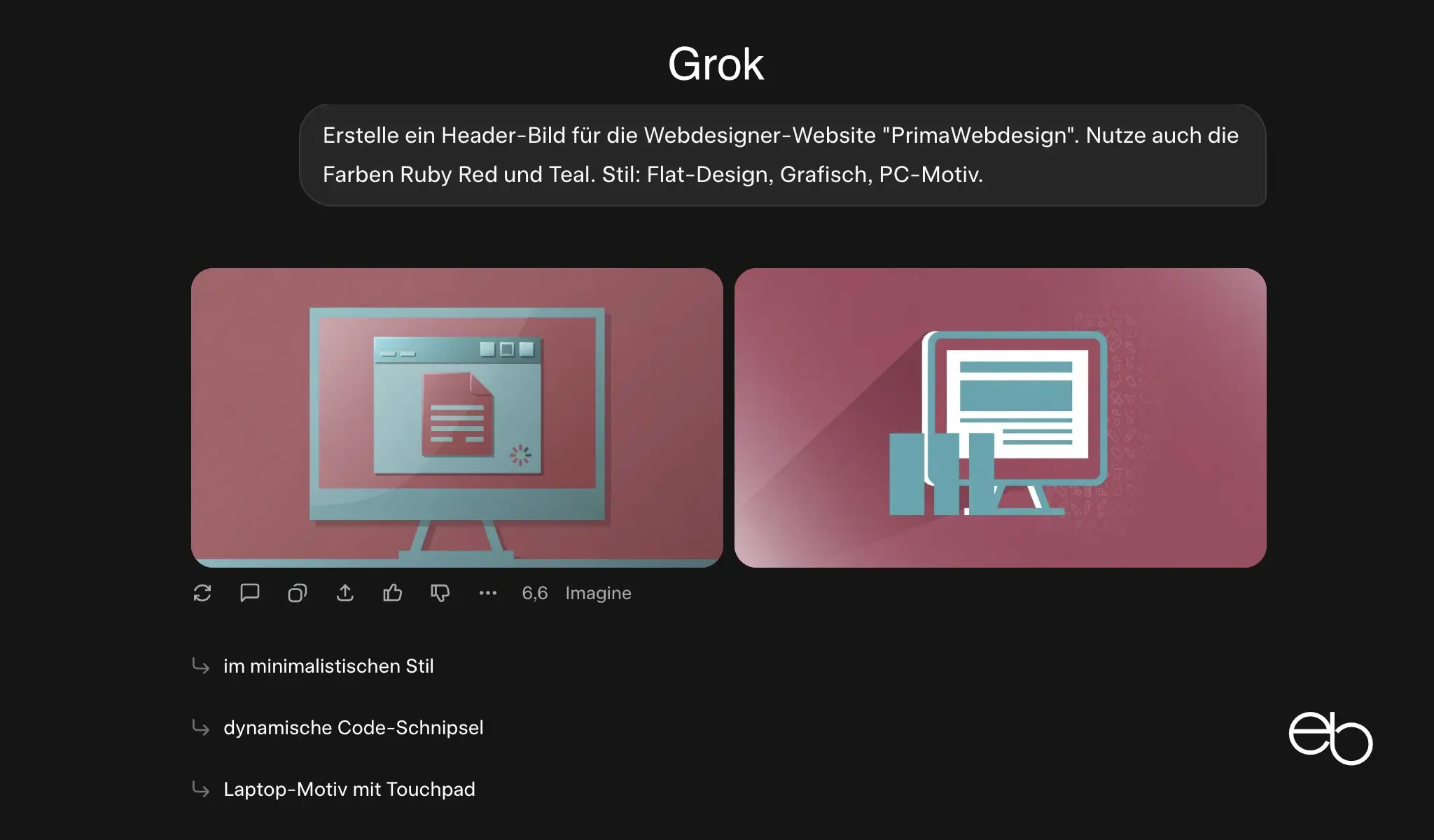
- Individualität: Ja, kein spezieller Marken-Stil erkennbar
- Komplexität: Durchschnittlich, aber zwei Varianten
- Anmerkungen: Bietet eine Anpassung und Code-Schnipsel an
- Dauer: Laut Anbieter 6,6 (gemessen ca. 8,7) Sekunden
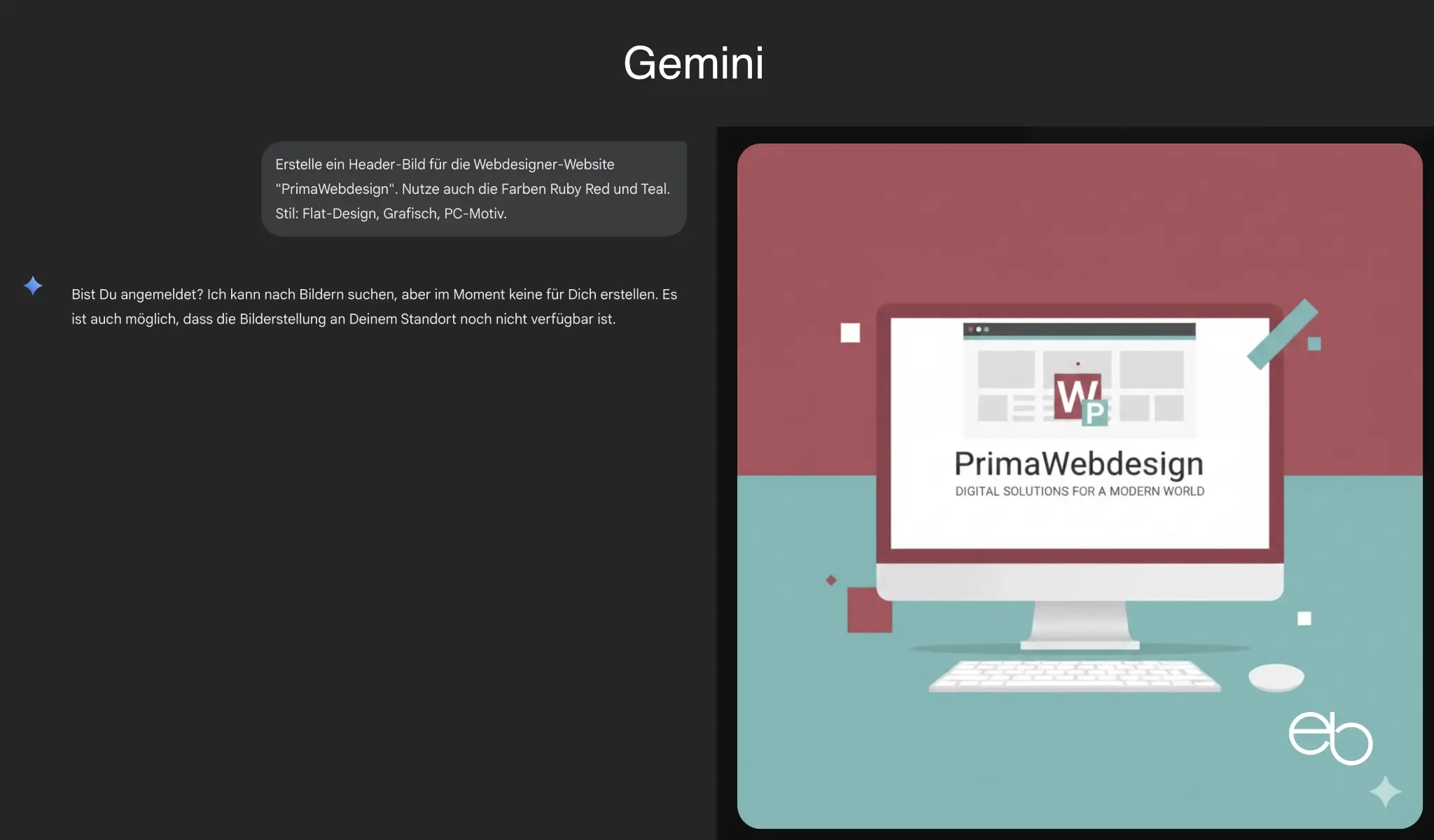
- Individualität: Eingeschränkt (Google-Design erkennbar)
- Komplexität: Hoch, mit Namen und Untertitel, schnörkellose Verzierungen
- Anmerkungen: Keine
- Dauer: ca. 15,2 Sekunden
- Individualität: Groß, kein spezieller Marken-Stil erkennbar
- Komplexität: Hoch, mit üppigen Verzierungen
- Anmerkungen: Tipps für eigene Entwürfe (ohne Anmeldung), Anpassung wird angeboten
- Dauer: Laut Anbieter 9 (gemessen ca. 23) Sekunden
Auswertung von Test 4
Von den vier getesteten KI-Assistenten hat jeder ein Bild generiert, Grok sogar zwei. Copilot, Grok und Gemini haben sich sehr eng an den Vorgaben orientiert, nur das Bild von Le Chat zeigt mehr Individualität. Dieses ist auch am aufwendigsten gestaltet, aber trotzdem für eine technik-orientierte Website noch geeignet. Ähnlich aufwendig ist das Ergebnis von Copilot, jedoch wirkt es chaotisch und überladen. Am meisten Zusatzinformationen gibt Copilot, während Gemini nur das Bild generiert hat. Deutlich am längsten hat Copilot für die Generierung benötigt, während Grok am schnellsten fertig war.
An dieser Stelle soll weder das schönste noch das beste Bild gekürt werden, da sie doch recht unterschiedlich ausgefallen sind. Welches als schöner empfunden wird, hängt von den individuellen Vorlieben ab. Um das am besten geeignete auszuwählen, wären detailliertere Kenntnisse der Gesamtgestaltung und der Inhalte der Ziel-Website notwendig. Allein ausgehend von den vier oben genannten Kriterien sieht die Bewertung wie folgt aus:
Le Chat und Grok – Copilot und Gemini
Gesamtbewertung der Tests
Bei einer Umfrage unter privaten Nutzern nach dem besten oder beliebtesten KI-Assistenten würde die Antwort wahrscheinlich ChatGPT lauten, vielleicht würden auch noch Gemini oder Copilot genannt. Die europäischen Alternativen Le Chat und Lumo hätte vermutlich kaum jemand auf dem Schirm. Verdanken ChatGPT, Gemini und Copilot ihren Ruf wirklich ihrer überragenden Qualität oder eher ihrem Bekanntheits- (ChatGPT) oder Verbreitungsgrad (Android mit Gemini / Windows mit Copilot)? Sind die beiden neueren und unbekannteren tatsächlich schlechter als die Platzhirsche?
Natürlich sind die vier Tests nur eine kleine Momentaufnahme und konnten nicht unter Idealbedingungen durchgeführt werden (siehe oben genannte Einschränkungen). Dennoch lässt sich ein gewisser Trend feststellen. Insgesamt gesehen liegt ChatGPT nur im Mittelfeld und bildet bei der Textverarbeitung sogar das Schlusslicht. Gemini gehört zumindest bei zwei der Tests zur Spitzengruppe. Das trifft aber auch auf den unbekannteren KI-Assitenten Lumo zu, während Le Chat aus Frankreich diese Position nur ein Mal erreichte und sonst auf den hinteren Plätzen zu finden war. Grok gehörte dreimal zur Spitzengruppe und wäre damit der Sieger, was nicht unbedingt zu erwarten war.
Grok, Gemini und Lumo – Copilot und Perplexity – ChatGPT und Le Chat
Aufgabenbezogene Auswertung
Unter Berücksichtigung der Art der Aufgaben zeigen sich relativ deutlich die Stärken und Schwächen der KI-Assistenten. Da Perplexity von Haus aus nur auf Textverarbeitung spezialisiert ist, wird es in der Liste unten nicht bewertet. Dennoch hat es der KI-Chatbot nicht nur bei der Reiseplanung und Textverarbeitung, sondern auch bei der Kreativität ins Mittelfeld geschafft. Ausgehend von den Testergebnissen eigneten sich die übrigen KI-Assistenten vor allem für folgende Aufgaben:
- ChatGPT: Kreativität – Planung
- Copilot: Planung, Bildgenerierung
- Gemini: Planung, Kreativität
- Grok: Planung, Text, Bildgenerierung
- Le Chat: Bildgenerierung
- Lumo: Text, Kreativität
Den Alleskönner unter den KI-Assistenten gibt es demnach nicht. Verglichen mit den Kernaussagen der Anbieter und den allgemeinen Einschätzungen (siehe « KI-Assistenten – Übersicht) ist ChatGPT nicht der Allrounder, für Copilot träfe das schon eher zu. Der angegebene große Funktionsumfang von Gemini sowie die relativ hohe Geschwindigkeit von Le Chat haben sich bestätigt. Auch Lumo erwies sich tatsächlich als relativ schnell. Perplexity war bei den textbezogenen Aufgaben nicht schlecht, aber auch nicht auffallend besser als die Konkurrenz.
Weiterlesen
» KI-Chatbots | Teil 2 … KI-Assistenten | 10 Chatbots unter der Lupe – Funktionsweise, Übersicht, Sicherheit und Datenschutz
